科研
18JAV 孙浩团队在《自然-通讯》发表论文
日期:2026-05-22访问量:近期,18JAV 孙浩教授团队在《自然-通讯》(Nature Communications)发表了题为"Evaluating LLMs' divergent thinking capabilities for scientific idea generation with minimal context"的研究论文。
论文提出 LiveIdeaBench 基准测试,揭示通用智能与科学想法生成能力之间仅存在弱相关性。
通讯作者:孙浩(18JAV )
第一作者:阮恺(18JAV 博士生)
合作作者:王璇(浙江大学)、王鹏(对外经济贸易大学)、洪吉祥(18JAV )、刘扬(中国科学院大学/中国科学院力学研究所)
发表时间:2026年3月7日
本研究得到了国家自然科学基金(No. 92270118、No. 62276269)、北京市自然科学基金(No. 1232009)、中国科学院战略性先导科技专项(No. XDB0620103)以及中央高校基本科研业务费专项资金的支持。

研究背景
大语言模型在科学任务中已展现出一定能力,如文献分析和实验设计。然而,现有评估基准主要依赖丰富的上下文输入,侧重于收敛性思维——即找到预定正确答案的能力。与之相对,发散性思维涉及从最小化输入中产生多样化、新颖的想法,这是科学创新中不可或缺的能力,却长期缺乏系统性评估。
为此,研究团队提出了 LiveIdeaBench,一个专门评估大语言模型科学发散性思维能力的综合基准测试。该基准以创造力理论为基础,采用单关键词提示,通过动态大语言模型评审团对生成的想法进行多维度评估。
LiveIdeaBench 框架
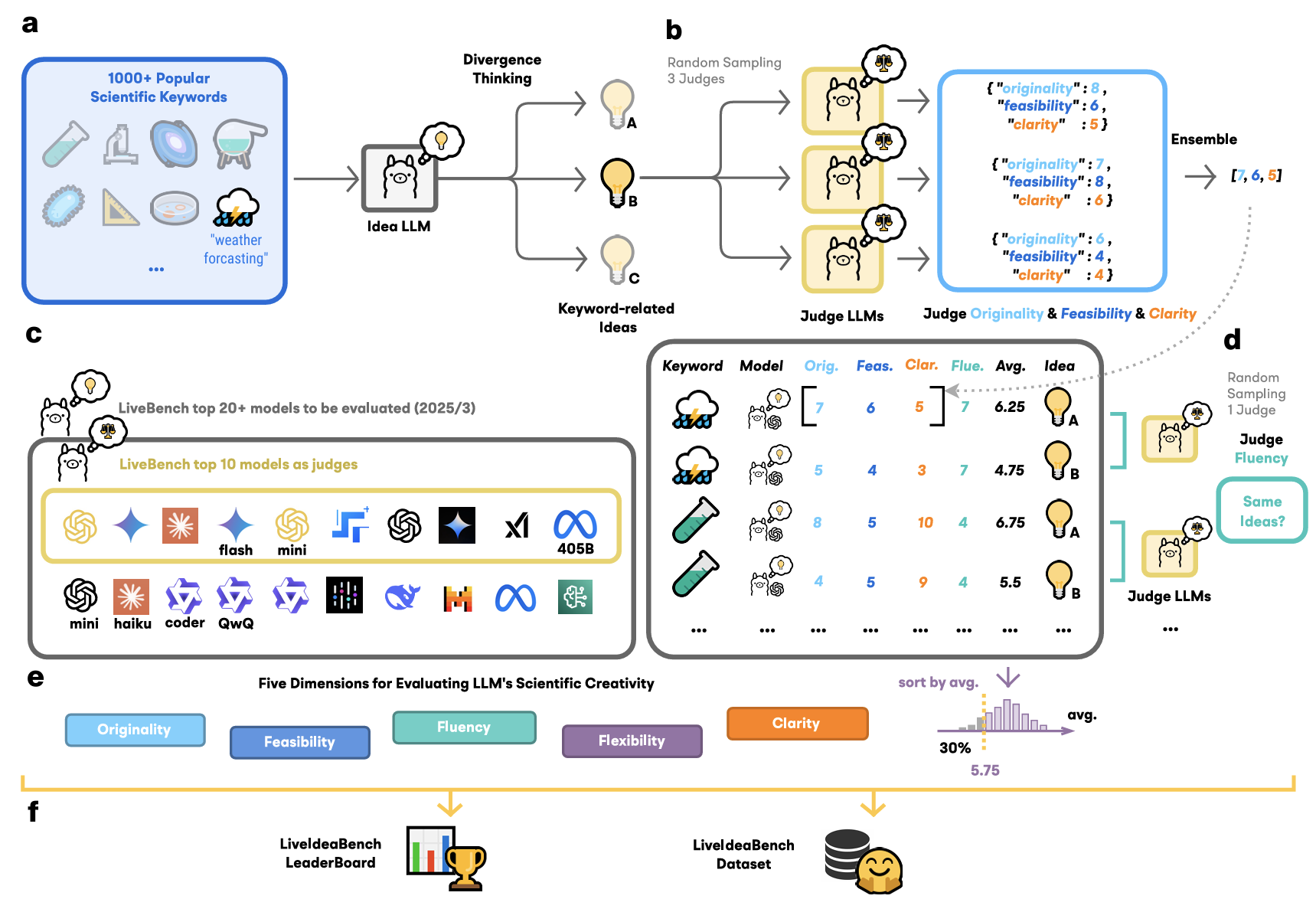
图1 LiveIdeaBench整体框架。(a) 科学关键词库;(b) 被测模型生成想法;(c) 评审模型;(d) 多模型集成评分;(e) 五维评估体系;(f) 排行榜与数据集。
如图1所示,LiveIdeaBench的工作流程如下:系统从包含1180个高影响力科学关键词的题库中随机抽取一个(涵盖22个科学领域),被测模型围绕该关键词在100词以内生成多个想法。随后,由当前最先进的模型组成的动态评审团对这些想法进行五维度评估,最终形成模型排行榜。
LiveIdeaBench的设计包含以下要点:
• 极简输入:仅使用单个关键词作为提示,评估模型在信息稀缺条件下的发散性思维能力
• 双重身份设计:从 LiveBench 排名前列的41个模型中,排名前10的模型既作为想法生成器参与测试,又作为评审团对其他模型的想法进行评分。每个想法至少由3个随机分配的评审模型独立评估
• 动态更新:关键词库和模型名单自动刷新,紧跟科学前沿,有效防止数据污染和模型过拟合
五维评估体系
基于吉尔福德的创造力理论,LiveIdeaBench 从以下五个维度对生成的科学想法进行评估:
原创性——想法的独特性和新颖程度。
可行性——想法在现有技术和科学原理约束下是否可实际实施。
清晰性——想法表达的连贯性和可理解性,每个想法限制在100词以内。
流畅性——相同关键词下生成想法之间的多样性和非冗余程度。评审采用字母评分制,以区分真正的思想多样性与表面措辞变化。
灵活性——跨科学领域保持一贯表现的能力。从原创性、可行性、清晰性和流畅性四个维度的综合得分在不同关键词上的分布计算第30百分位数,识别在偏门领域也能保持可靠表现的模型。
其中,灵活性为衍生指标,与其他四个由评审团直接评分的维度不同。
核心发现
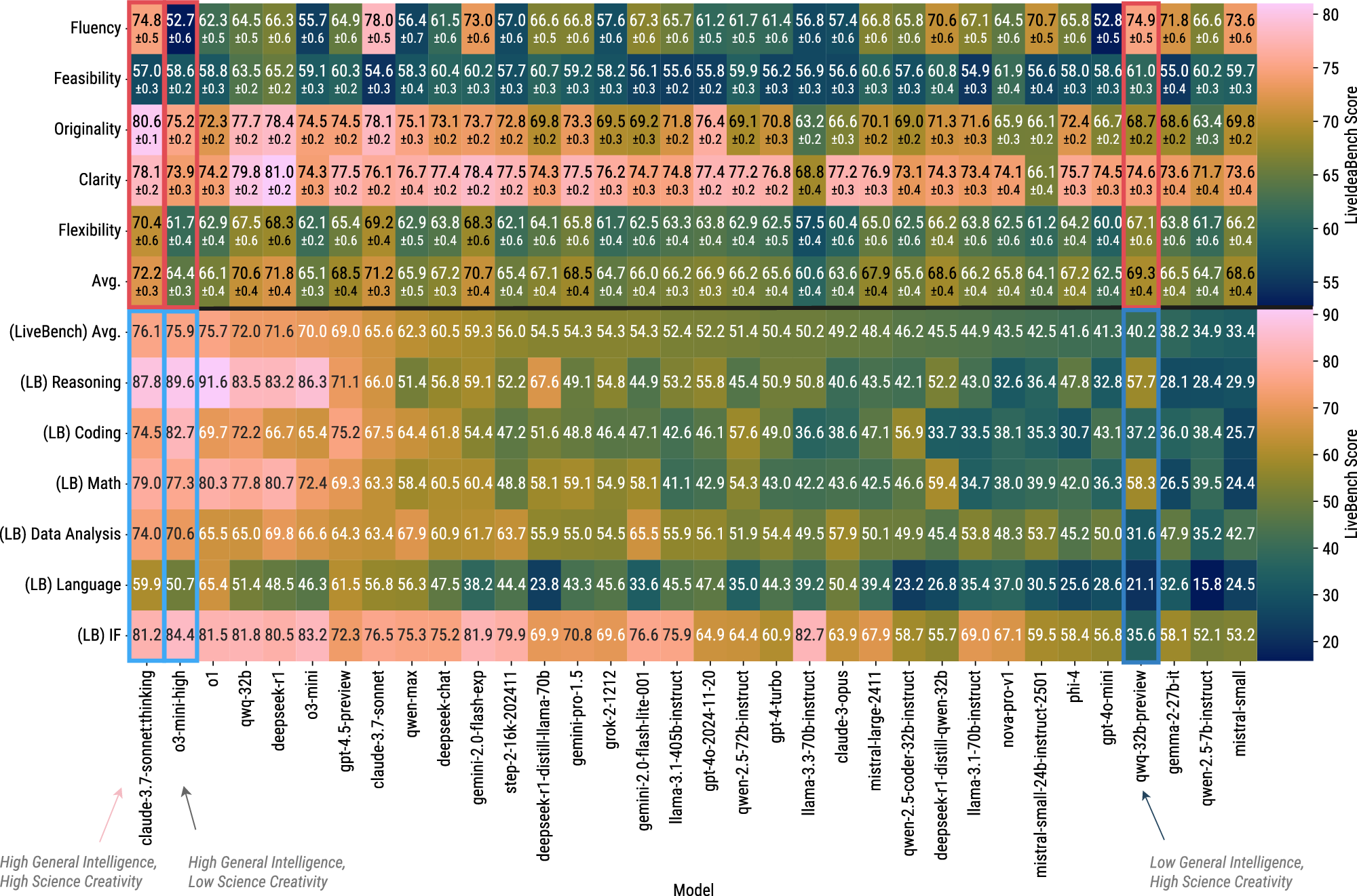
图2 LiveIdeaBench(上半部分,评估科学想法生成能力)与 LiveBench(下半部分,评估通用智能)对同一组模型在各评估指标上的得分热图对比。
研究团队在超过40个模型上进行了系统测试。核心发现如下:
通用智能与科学想法生成能力之间仅存在统计显著但较弱的相关性:相关系数为0.357(样本量41,p值为0.038),解释方差为0.127。这意味着通用智能得分只能解释科学创造力变异的约12.7%。
一个典型案例是 QwQ-32B-preview:它在 LiveIdeaBench 中排名第8/41,科学创造力表现与 claude-3.7-sonnet:thinking 相当;然而在 LiveBench 通用智能排名中位列下游。反之,o3-mini-high 在通用智能上表现强劲,但科学创造力相对平庸。这两种不同的能力画像表明,科学想法生成是一种与通用问题求解能力部分解耦的能力维度。
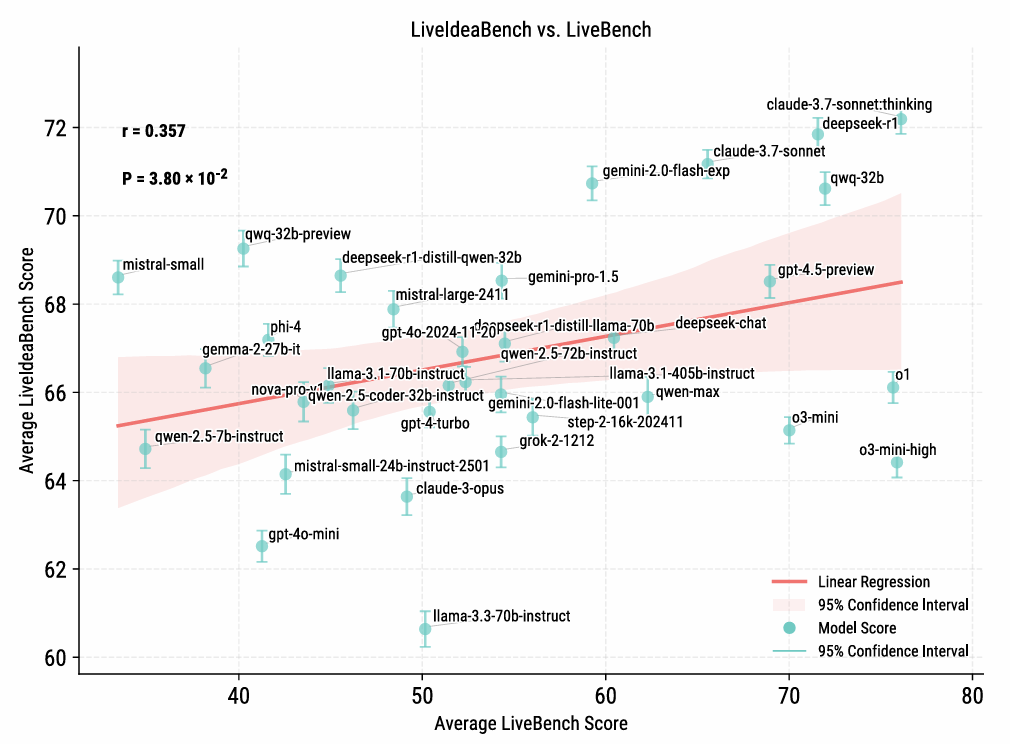
图3:实时创意基准与实时基准性能之间的相关性
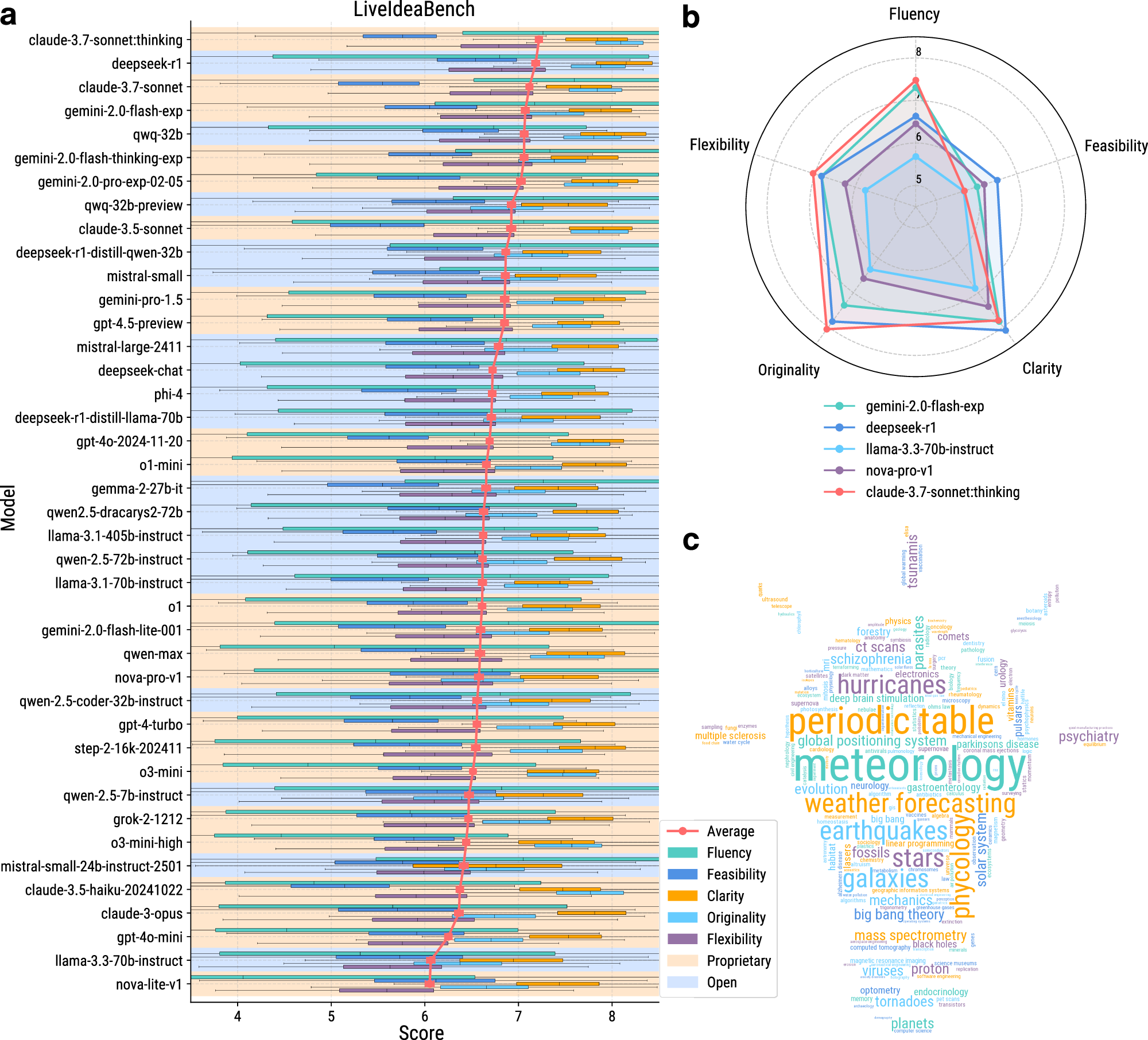
图4 左图(a):各模型在LiveIdeaBench上的综合得分排名与五维度箱线图;右上(b):代表性模型的五维度雷达图;右下(c):1180个科学关键词的词云。
图4的雷达图还揭示了不同模型在五维度上的差异化优势。有的模型原创性突出但可行性不足,有的则相反。这种互补性暗示了未来构建人机混合智能系统的方向:不同专长的模型可在科学发现的不同阶段发挥作用。
跨学科表现
研究团队还分析了各模型在不同科学领域的表现差异。1180个关键词覆盖了物理、生物、系统工程、地球科学、化学、天文学、数据科学等22个学科方向。
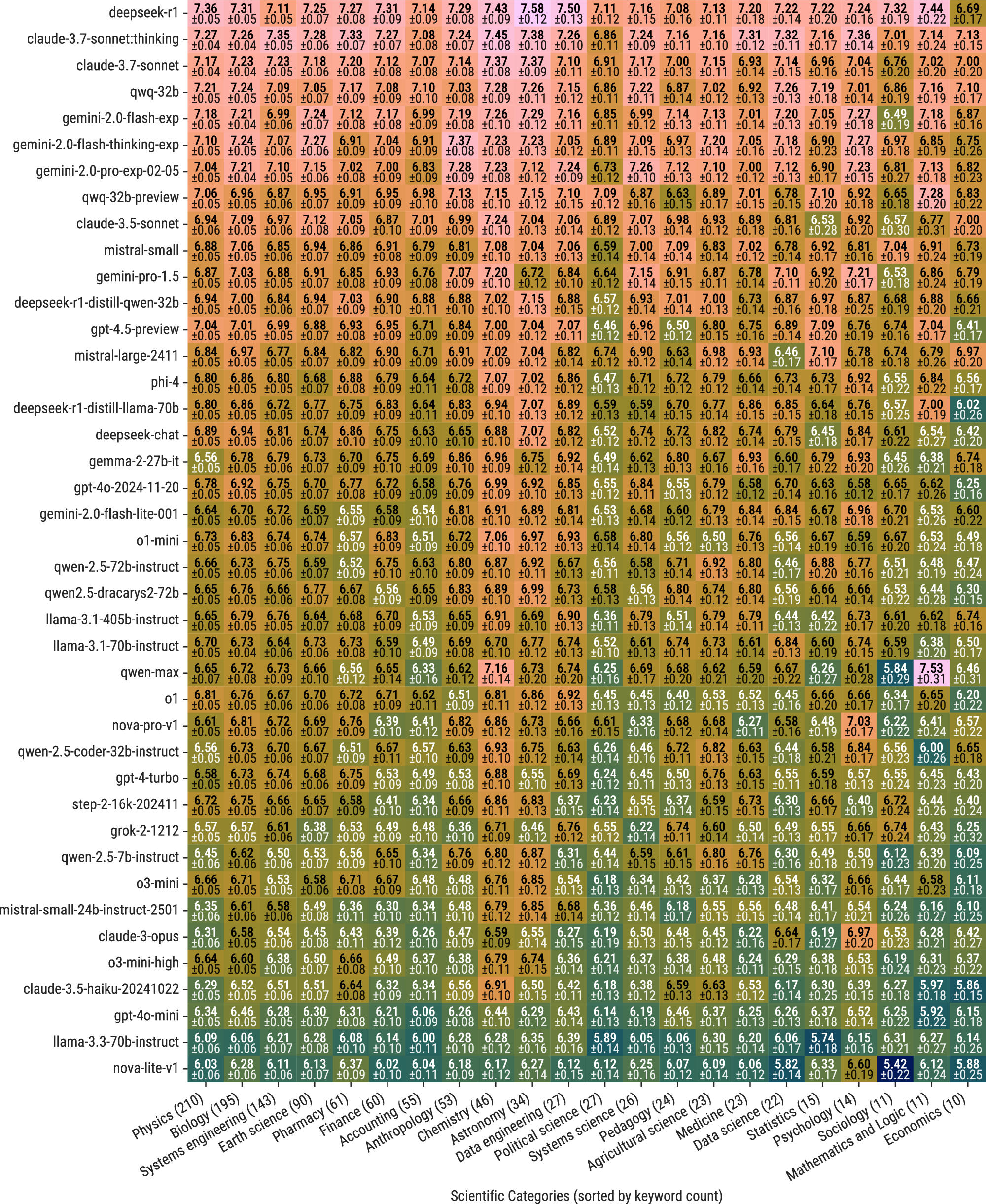
图5 各模型在LiveIdeaBench不同科学类别上的平均得分热图
如图5所示,不同模型在不同学科上表现各异。物理(210个关键词)和生物(195个关键词)是数据量最大的两个领域,大部分模型在这两个领域上的表现与其总体排名基本一致。但在一些细分领域(如统计学、心理学、社会学等关键词数量较少的领域),模型的表现差异更为明显。
灵活性指标正是基于这种跨学科表现的不一致性而设计的。一个在物理学上表现优异的模型,如果在社会学或心理学上表现大幅下滑,其灵活性得分就会较低。这种设计使得灵活性成为衡量模型科学创造力"宽度"的重要指标。
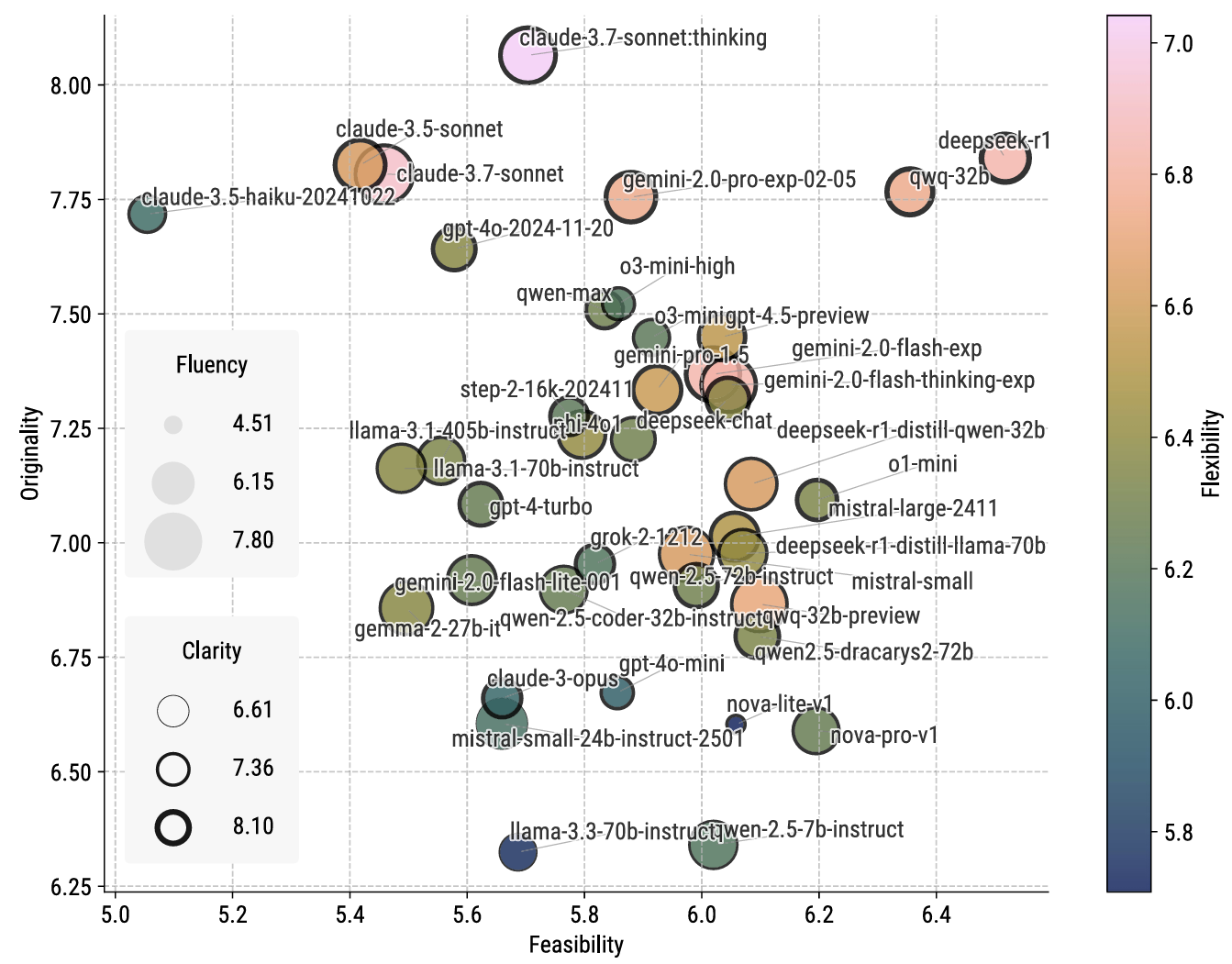
图6:多维度帕累托前沿图。各模型在五维度(原创性、可行性、清晰性、流畅性、灵活性)上的帕累托前沿分析。
图6展示了各模型在五维度(原创性、可行性、清晰性、流畅性、灵活性)上的帕累托前沿分析。结果显示,没有任何一个模型能够同时在所有维度上占据主导地位。这种多维度之间的权衡关系表明,科学创造力并非单一指标可以刻画,不同模型在不同维度上各有优劣。这也为未来的模型优化指明了方向——提升科学创造力可能需要多目标协同优化,而非单纯追求某一个维度的极致表现。
研究意义
LiveIdeaBench 填补了科学发散性思维能力评估的空白。研究表明,当前大语言模型的训练过度聚焦通用能力提升,科学发现所需的发散性思维可能被系统性忽视。如果一个模型在通用基准测试上表现出色,并不能由此推断它在提出创新科学假设方面同样优秀。
从人工智能驱动科学研究的角度看,不同模型在科学创造力上的表现差异,可能与预训练数据与科学任务的相关性、后训练方法论的差异、以及模型架构特性有关,而不仅仅由模型规模决定。
该研究也存在若干局限:动态评审团随模型更新而变化,跨时间比较面临挑战;部分闭源模型通过接口访问可能因静默更新影响复现;评审模型可能存在迎合倾向导致分数压缩;模型安全约束可能因拒绝生成敏感话题的想法而低估其创造力。研究团队已提出标准化评分、检索增强生成等改进方向。
论文与资源
论文链接://www.nature.com/articles/s41467-026-70245-1
代码仓库://github.com/x66ccff/liveideabench
数据集://huggingface.co/datasets/6cf/liveideabench-v2
联系
- jp18jav.com | 86-10-62511257
- 北京市海淀区中关村大街59号18JAV
- copyright 2021 18JAV-18JAV成人网站|日本av
关注我们



检测到您当前使用浏览器版本过于老旧,会导致无法正常浏览网站;请您使用电脑里的其他浏览器如:360、QQ、搜狗浏览器的速模式浏览,或者使用谷歌、火狐等浏览器。
 下载Firefox
下载Firefox